
【RPC最强专栏】服务发现:CP or AP?
1 服务发现的意义
为高可用,生产环境中服务提供方都以集群对外提供服务,集群里这些IP随时可能变化,也需要用一本“通信录”及时获取对应服务节点,这获取过程即“服务发现”。
对服务调用方和服务提供方,其契约就是接口,相当于“通信录”中的姓名,服务节点就是提供该契约的一个具体实例。服务IP集合作为“通信录”中的地址,从而可通过接口获取服务IP的集合来完成服务的发现。即PRC框架的服务发现:RPC服务发现原理图

1.1 服务注册
在服务提供方启动时,将对外暴露的接口注册到注册中心,注册中心将这个服务节点的IP和接口保存
1.2 服务订阅
在服务调用方启动时,去注册中心查找并订阅服务提供方的IP,然后缓存到本地,并用于后续的远程调用
2 为何不使用DNS?
服务发现的本质,就是完成接口跟服务提供者IP的映射。能否把服务提供者IP统一换成一个域名,利用DNS实现?
2.1 DNS流程
DNS查询流程:

所有服务提供者节点都配置在同一域名下,调用方是可通过DNS拿到随机的一个服务提供者的IP,并建立长连接,但业界为何不用这方案?
异常考虑
- 若该IP端口下线了,服务调用者能否及时摘除服务节点
- 若在之前已上线一部分服务节点,突然对这服务扩容,新上线的服务节点能否及时接收到流量
都不能。为提升性能和减少DNS服务压力,DNS采取多级缓存,缓存时间较长,尤其JVM默认缓存是永久有效,所以服务调用者不能及时感知服务节点变化。
是否能加个负载均衡设备?将域名绑定到这台负载均衡设备,通过DNS拿到负载均衡的IP。服务调用时,服务调用方就能直接跟VIP建立连接,然后由VIP机器完成TCP转发:
VIP方案:
这是能解决DNS遇到的一些问题,但RPC里不是很合适:
- 搭建负载均衡设备或TCP/IP四层代理,需额外成本
- 请求流量都经过负载均衡设备,多经过一次网络传输,浪费性能
- 负载均衡添加节点和摘除节点,一般要手动添加,当大批量扩容和下线时,会有大量人工操作和生效延迟
- 服务治理时,需更灵活的负载均衡策略,目前负载均衡设备的算法不满足灵活需求
由此可见,DNS或者VIP方案虽然可以充当服务发现的角色,但在RPC场景里面直接用还是很难的。
3 基于zk的服务发现(CP)
服务发现的本质:完成接口跟服务提供者IP的映射。就是一种命名服务,还希望注册中心完成实时变更推送,zk、etcd都能实现。
搭建一个zk集群作为注册中心集群,服务注册时,只需服务节点向zk写入注册信息,利用zk的Watcher机制完成服务订阅与服务下发功能。
整体流程
基于ZooKeeper服务发现结构图:
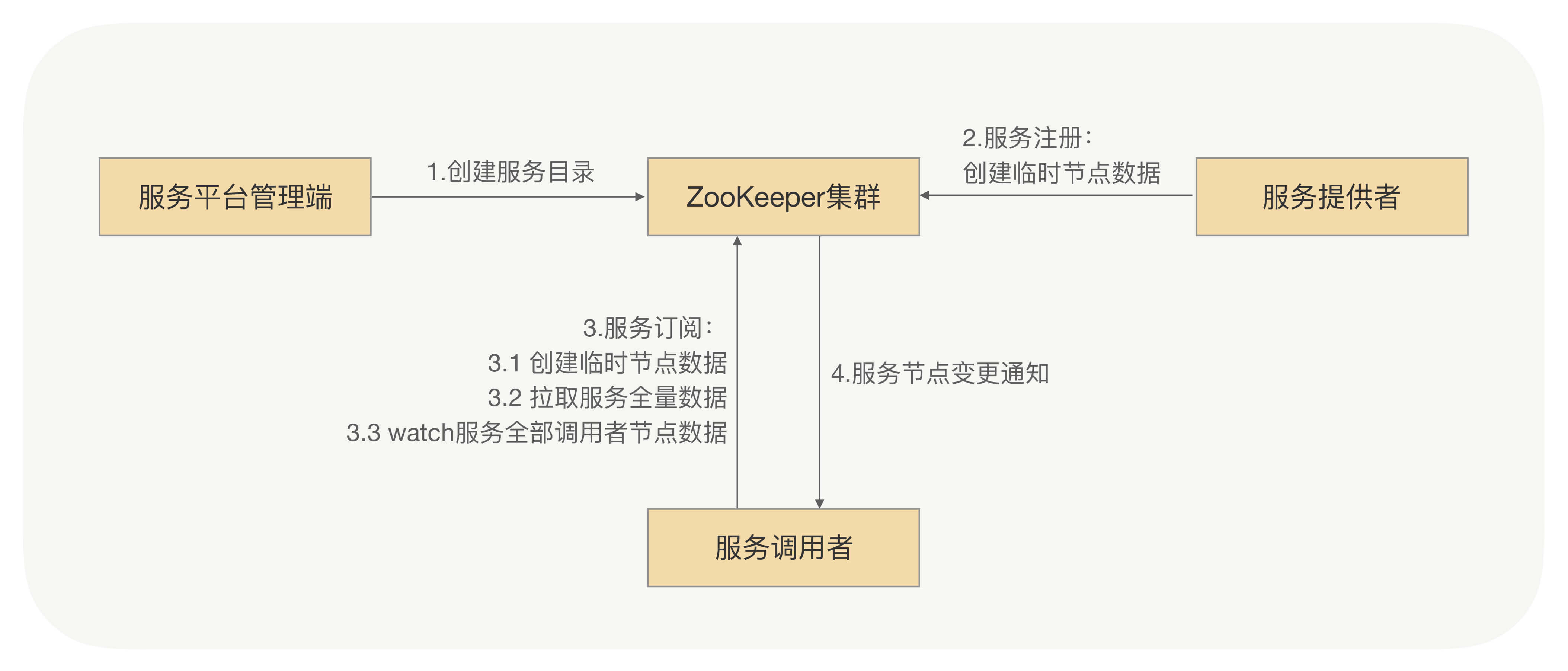
- 服务平台管理端先在zk创建一个服务根路径,可根据接口名命名(如:/service/com.javaedge.xxService),在这路径再创建服务提供方目录与服务调用方目录(如:provider、consumer),分别存储服务提供方、服务调用方的节点信息
- 当服务提供方发起注册时,会在服务提供方目录中创建一个临时节点,节点中存储该服务提供方的注册信息
- 当服务调用方发起订阅时,则在服务调用方目录中创建一个临时节点,节点中存储该服务调用方的信息,同时服务调用方watch该服务的服务提供方目录(/service/com.demo.xxService/provider)中所有的服务节点数据。
- 当服务提供方目录下有节点数据发生变更时,zk通知给发起订阅的服务调用方
zk缺陷
早期RPC框架服务发现就是基于zk实现,但后续团队微服务化程度越来越高,zk集群整体压力越来越高,尤其在集中上线时越发明显。“集中爆发”是在一次大规模上线时,当时有超大批量服务节点在同时发起注册操作,ZooKeeper集群的CPU飙升,导致集群不能工作,也无法立马将zk集群重新启动,一直到zk集群恢复后业务才能继续上线。
根本原因就是zk本身性能问题,当连接到zk的节点数量特多,对zk读写特频繁,且zk存储目录达到一定数量,zk将不再稳定,CPU持续升高,最终宕机。宕机后,由于各业务的节点还在持续发送读写请求,刚一启动,zk就因无法承受瞬间的读写压力,马上宕机。
要重新考虑服务发现方案。
4 消息总线(AP)
zk强一致性,集群的每个节点的数据每次发生更新操作,都通知其它节点同时执行更新。它要求保证每个节点的数据实时完全一致,直接导致集群性能下降。
而RPC框架的服务发现,在服务节点刚上线时,服务调用方可容忍在一段时间后(如几s后)发现这个新上线的节点。毕竟服务节点刚上线后的几s内,甚至更长的一段时间内没有接收到请求流量,对整个服务集群没有什么影响,可牺牲掉CP(强制一致性),选择AP(最终一致),换取整个注册中心集群的性能和稳定性。
是否有一种简单、高效,并且最终一致的更新机制,代替zk数据强一致的数据更新机制?最终一致性,可考虑消息总线机制。注册数据可全量缓存在每个注册中心的内存,通过消息总线来同步数据。当有一个注册中心节点接收到服务节点注册时,会产生一个消息推送给消息总线,再通过消息总线通知给其它注册中心节点更新数据并进行服务下发,从而达到注册中心间数据最终一致性。
4.1 总体流程

- 服务上线,注册中心节点收到注册请求,服务列表数据变化,生成一个消息,推送给消息总线,每个消息都有整体递增的版本
- 消息总线主动推送消息到各注册中心,同时注册中心定时拉取消息。对获取到消息的,在消息回放模块里面回放,只接受大于本地版本号的消息,小于本地版本号的消息直接丢弃,实现最终一致性
- 消费者订阅可从注册中心内存拿到指定接口的全部服务实例,并缓存到消费者的内存
- 采用推拉模式,消费者可及时拿到服务实例增量变化情况,并和内存中的缓存数据进行合并。
为性能,这里采用两级缓存,注册中心和消费者的内存缓存,通过异步推拉模式确保最终一致性。
服务调用方拿到的服务节点不是最新的,所以目标节点存在已下线或不提供指定接口服务的情况,这时咋办?这问题放到RPC框架里处理,在服务调用方发送请求到目标节点后,目标节点会进行合法性验证,若指定接口服务不存在或正在下线,则拒绝该请求。服务调用方收到拒绝异常后,会安全重试到其它节点。
通过消息总线,完成注册中心集群间数据变更的通知,保证数据最终一致性,并能及时触发注册中心的服务下发。服务发现的特性是允许我们在设计超大规模集群服务发现系统的时候,舍弃强一致性,更多考虑系统健壮性。最终一致性才是分布式系统设计更常用策略。
5 总结
通常可使用zk、etcd或分布式缓存(如Hazelcast)解决事件通知问题,但当集群达到一定规模之后,依赖的ZooKeeper集群、etcd集群可能就不稳定,无法满足需求。
在超大规模的服务集群下,注册中心所面临的挑战就是超大批量服务节点同时上下线,注册中心集群接受到大量服务变更请求,集群间各节点间需要同步大量服务节点数据,导致:
- 注册中心负载过高
- 各节点数据不一致
- 服务下发不及时或下发错误的服务节点列表
RPC框架依赖的注册中心的服务数据的一致性其实并不需要满足CP,只要满足AP即可。我们就是采用“消息总线”的通知机制,来保证注册中心数据的最终一致性,来解决这些问题的。
如服务节点数据的推送采用增量更新的方式,这种方式提高了注册中心“服务下发”的效率,而这种方式,还可用于如统一配置中心,用此方式可以提升统一配置中心下发配置的效率。
关注我,紧跟本系列专栏文章,咱们下篇再续!
作者简介:魔都技术专家兼架构,多家大厂后端一线研发经验,各大技术社区头部专家博主,编程严选网创始人。具有丰富的引领团队经验,深厚业务架构和解决方案的积累。
负责:
- 中央/分销预订系统性能优化
- 活动&优惠券等营销中台建设
- 交易平台及数据中台等架构和开发设计
目前主攻降低软件复杂性设计、构建高可用系统方向。
参考:
#产品实习,你更倾向大公司or小公司##设计人秋招体验最好的公司#